

风离不摆烂学习日志Day17 Java 异步线程池 测压
风离不摆烂学习日志Day17 Java 异步线程池 测压
前情提要:
为了验证上一篇所提到的线程池工具类 在实际业务场景下的可行性 设计了 多个对照组 使用Jmeter测压软件 完成对比实验
实验流程

对比组一 串行组
@RequestMapping("/testSync")
public void test() throws InterruptedException {
long start = System.currentTimeMillis();
System.out.println("开始执行任务");
// 1s
Thread.sleep(1000);
System.out.println("第一个任务执行完成");
// 3s
Thread.sleep(3000);
System.out.println("第二个任务执行完成");
// 5s
Thread.sleep(5000);
System.out.println("第三个任务执行完成");
// 2s
Thread.sleep(2000);
System.out.println("第四个任务执行完成");
System.out.println("任务执行完成,耗时:" + (System.currentTimeMillis() - start) + "ms");
}
串行组耗时 11s

现在我们使用Jmeter 分别创建 20 个 200 个 250个 并发线程 看看结果 (PS: 查询资料可知 tomcat默认并发数(最大请求数为200) )
20个

200个

这个是上一次结果累加的到的 可以看到 目前一切正常
250个

这里可以清楚的看到 Tomcat默认的并发数 的确是200 超过两百的 就会排队 等候之前的 线程执行完毕之后才会去执行剩余线程 这次平均时间为 13s
串行组小结
- 验证了Tomcat的默认最大请求数为200
- 为异步组提供了对照 (
控制变量法)
对比组二 异步并行组
private final ThreadPoolExecutor executor = ExecutorUtils.getThreadPoolExecutorInstance(); // 线程组
@RequestMapping("/testAsync")
public void testAsync() throws InterruptedException {
long start = System.currentTimeMillis();
System.out.println("开始执行任务");
// 1s
CompletableFuture futureOne = CompletableFuture.supplyAsync(() -> {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("第一个异步任务执行完成");
return null;
}, executor);
// 3s
CompletableFuture futureTwo = CompletableFuture.supplyAsync(() -> {
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("第二个异步任务执行完成");
return null;
}, executor);
// 5s
CompletableFuture futureThree = CompletableFuture.supplyAsync(() -> {
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("第三个异步任务执行完成");
return null;
}, executor);
//需要等待所有异步任务执行完成 才能执行下面的同步任务
CompletableFuture[] completableFutures = Arrays.asList(futureOne, futureTwo,futureThree).toArray(new CompletableFuture[0]);
ExecutorUtils.batchExec(completableFutures); //批量执行
// 2s
Thread.sleep(2000);
System.out.println("第四个同步任务执行完成");
System.out.println("任务执行完成,耗时:" + (System.currentTimeMillis() - start) + "ms");
}
异步并行组耗时7s


同时我们可以看到 设置的最大cpu核数为 16核 核心CPU数 为 8*0.75 = 12核
同样的 我们分别模拟 20 个 200 个 250个 并发线程 看看结果
20

这里出现了一个很有意思的现象:

这个接口 的耗时逐渐增加
最开始 第一个请求是 7s 最后一个请求的时间达到了 19s

这里来分析一下这个问题出现的原因:
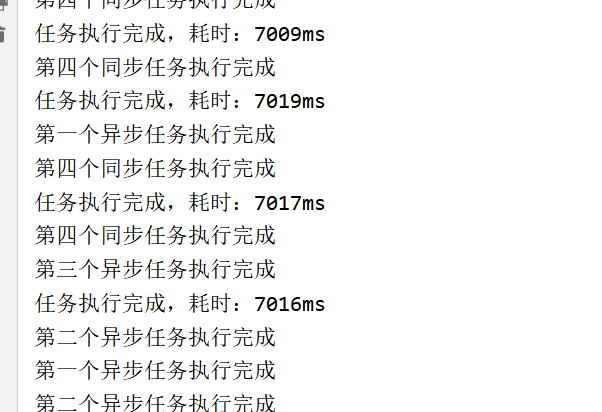
我们可以看到前4个请求的 执行耗时 几乎都是 7s 从第五个开始逐渐 每多一个请求 请求时长 多 1s
改造一下代码 打印一下 线程Id 和Name 看看 是否合理运用了
@RequestMapping("/testAsync")
public void testAsync() throws InterruptedException {
long start = System.currentTimeMillis();
System.out.println("开始执行任务");
// 1s
CompletableFuture futureOne = CompletableFuture.supplyAsync(() -> {
try {
System.out.println();
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("futureOne "+Thread.currentThread().getId()+"---"+Thread.currentThread().getName()+"---"+"第一个异步任务执行完成");
return null;
}, executor);
// 3s
CompletableFuture futureTwo = CompletableFuture.supplyAsync(() -> {
try {
Thread.sleep(3000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("futureTwo "+Thread.currentThread().getId()+"---"+Thread.currentThread().getName()+"---"+"第二个异步任务执行完成");
return null;
}, executor);
// 5s
CompletableFuture futureThree = CompletableFuture.supplyAsync(() -> {
try {
System.out.println();
Thread.sleep(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
//获取当前线程名称
System.out.println("futureThree "+Thread.currentThread().getId()+"---"+Thread.currentThread().getName()+"---"+"第三个异步任务执行完成");
return null;
}, executor);
//需要等待所有异步任务执行完成 才能执行下面的同步任务
CompletableFuture[] completableFutures = Arrays.asList(futureOne, futureTwo,futureThree).toArray(new CompletableFuture[0]);
ExecutorUtils.batchExec(completableFutures); //批量执行
// 2s
Thread.sleep(2000);
System.out.println(Thread.currentThread().getId()+"---"+Thread.currentThread().getName()+"---"+"第四个同步任务执行完成");
System.out.println("任务执行完成,耗时:" + (System.currentTimeMillis() - start) + "ms");
}
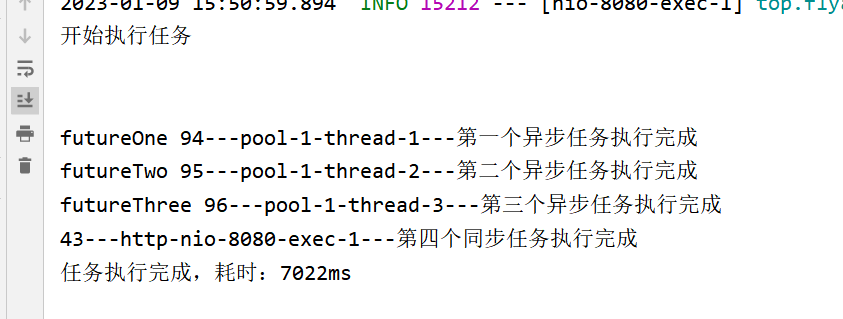
同样起20个线程

可以看到 这个线程的最大线程号 就是我们设置 的最大 核心cpu数 12
目前我们知道 只有12个线程在执行任务 且最耗时的任务为 5s 即其中一个线程必定会在 5s 之后才会执行下一个任务 再来看看 刚刚的超过4个请求之后 耗时就增加1秒 我们可以很容易的分析出 原因 4*3 =12 核 吃满了12个线程 没有多余的线程去处理异步任务 所以他们陷入了等待 假设不考虑执行损耗 我们可以列出如下表格
thread 1 =》1s
thread 2 =》3s
thread 3 =》5s
thread 4 =》1s
thread 5 =》3s
thread 6 =》5s
thread 7 =》1s
thread 8 =》3s
thread 9 =》5s
thread 10 =》1s
thread 11 =》3s
thread 12 =》5s
所以第二轮请求会在 1s之后才开始 所以 每次都累加1s(有线程还在被占用中)
所以就目前来看 公共的线程池 显然是个错误的方向 我们只利用到了一个线程池(12线程)这里我也认识到了之前犯的错误 目前的解决方案 需要 充分利用到所有线程池 即默认的200个
代码优化 充分利用200个线程池
上述例子: 理论上 充分利用上200个线程池 (以我电脑配置来举例)最多同时处理 200*4 = 800个并发请求
/**
* 获取线程池 初始化
* @return
*/
public static ThreadPoolExecutor getThreadPoolExecutorInstance() {
//每一次都新建
return new ThreadPoolExecutor(corePoolSize,
maxPoolSize, keepAliveTime,
java.util.concurrent.TimeUnit.SECONDS,
new java.util.concurrent.ArrayBlockingQueue<Runnable>(queueCapacity),
new java.util.concurrent.ThreadPoolExecutor.CallerRunsPolicy()); //.ThreadPoolExecutor.CallerRunsPolicy() 的意思是:如果线程池已经满了,那么就由调用者所在的线程来执行任务
}
20个

可以看到现在耗时正常了 也充分利用到了各个线程池
200个
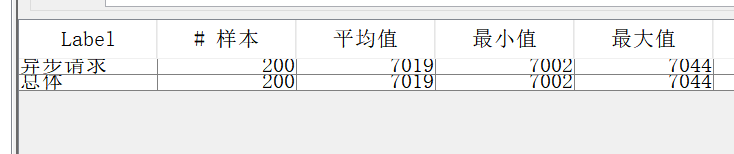
可以看到一切正常
250个 预测一波不会有任何问题

不出所料
由刚刚得到结论可知 我的电脑最大能处理 200*4 = 800 个并发请求
所以这次直接上850个线程


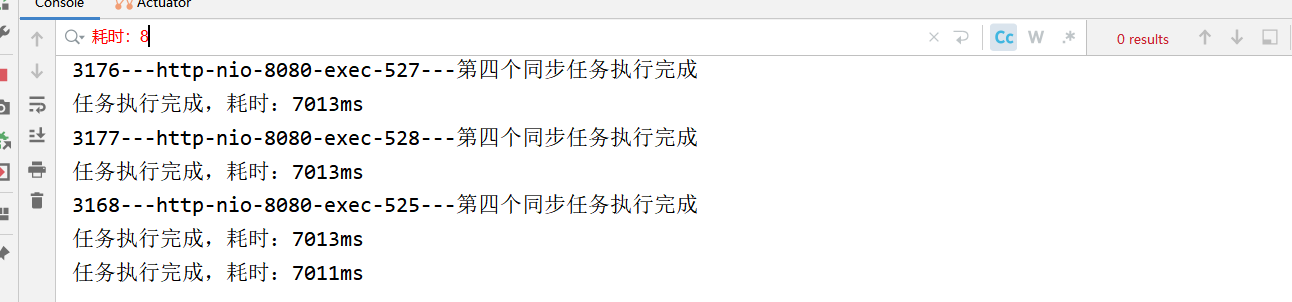
jmeter 测试显示数据 跟打印有很大偏差(Tomcat的排队等待机制 200一批) 这里以实际请求为主 可以看到850线程还是能稳定 7s
当然要继续测试下去 找到波动的点 这次直接上3000线程
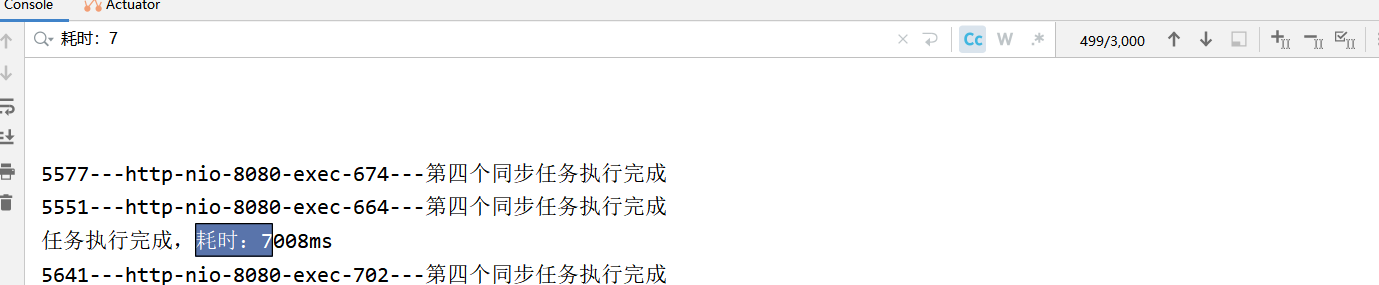
牛逼。。。还是全部耗时7s
那 1w呢 想来继续测试下去也没有意义了 因为一次只会 200个 多的都排队了…
到现在 基本上可以得到一些结论了
结论
- 线程池与线程之间的关系: 线程池是线程的集合 Tomcat默认最大创建200个线程池
- 最大并发数取决于服务器的配置 CPU核数 以及某接口中异步任务个数(这个会占用线程 而核心线程数又是由CPU决定的 故得出此结论)(某一接口并发)具体公式为 、
(cpu核心数/异步任务个数)* 200(Tomcat默认 可调) - 特别的 像那种1w 10w 这种高并发 其实都是分批进行的 比如并发数为800 他就会800一批来跑